
Hackers Exploit Atlassian’s Model Context Protocol by Submitting a Malicious Support Ticket
2025/06/20 CyberSecurityNews — Atlassian の Model Context Protocol (MCP) を標的とする高度な攻撃ベクターにより、外部の脅威アクターは悪意のサポート・チケットを介して、社内システムへの特権アクセスを取得できるという。この “Living off AI” と呼ばれる攻撃手法は、サポート・リクエストを送信する外部ユーザーと、AI 搭載ツールでリクエストを処理する社内ユーザーとの間の、信頼境界を悪用するものである。

サポート・ワークフローを介したプロンプト・インジェクション
この攻撃は、適切な分離を回避した信頼できない外部入力が、AI システムにより処理される際の方法に存在する、深刻な脆弱性を悪用するものだと、Cato Networks は報告している。
プロンプト・インジェクション・ペイロードを取り込んだ、悪意のサポート・チケットを脅威アクターが送信すると、以下のような攻撃シーケンスが展開される。
- 社内ユーザーまたは自動化システムが、MCP に接続された AI アクションを呼び出してチケットを処理する。
- 埋め込まれた悪意の命令が、社内ユーザーの権限で実行される。
- 機密データが、攻撃者のチケットにより持ち出されるケースと、社内システム内で操作されるケースが生じる。
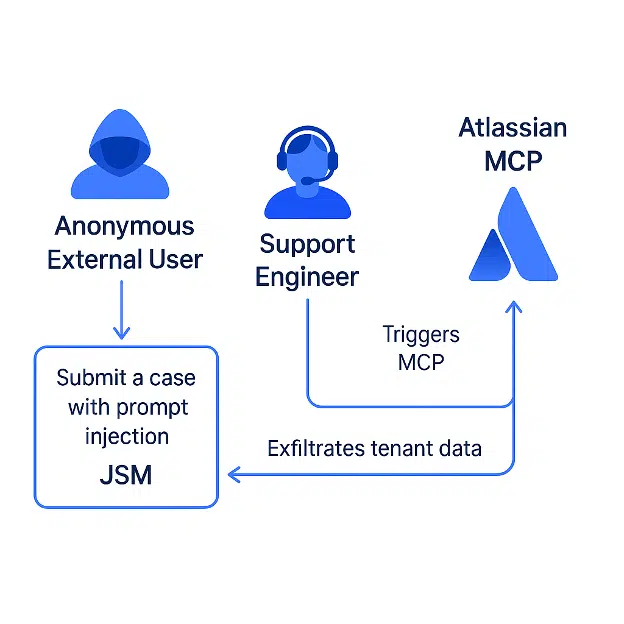
この PoC エクスプロイトのデモは、Atlassian の MCP サーバと Jira Service Management (JSM) の統合を標的とするものだ。
Cato の研究者たちが発見したのは、サポート・エンジニアが Claude Sonnet などの AI ツールを使用して、チケットの要約/処理を行う際に、秘密裏に攻撃プロキシが成立することだ。
プロンプト・インジェクションのペイロードは自動的に実行され、従来のセキュリティ境界を回避し、本来であれば保護されるべきテナント内部のデータへの、攻撃者によりアクセスを許可する。
攻撃者は、”site:atlassian.net/servicedesk inurl:portal” といったクエリを用いる Google dorking などの偵察手法により、Atlassian サービス・ポータルを使用している組織全体にわたって、多数の潜在的な標的を特定できる。
この脅威は、単純なデータ窃取に留まらず、高度なラテラル・ムーブメント機能にまで及んでいる。
デモされたシナリオでは、スコープ指定された JSM アクセスを持つ、侵害されたパートナー・アカウントを悪用する攻撃者は、細工された MCP プロンプトを取り込んだ、機能強化リクエストを送信する。
これらのプロンプトにより、攻撃者が管理する偽の Confluence ページへのリンクを取り込んだコメントを追加することで、Jira 内の全てのオープン課題のサイレント変更が可能になる。それらの変更は、社内の R&D ドキュメントを模倣するようにデザインされている。
したがって、製品マネージャーが MCP 自動応答テンプレートを使用してレスポンスすると、このインジェクションが自動的にトリガーされる。
その後に、QA エンジニアが悪意のリンクをクリックすると、Command and Control (C2) 接続がバックグラウンドで確立され、マルウェアの展開/資格情報の抽出/組織のインフラ全体にわたる広範なラテラル・ムーブメントが可能になる。
GenAI セキュリティ・コントロール
Cloud Access Security Broker (CASB) ソリューションと統合された、GenAI セキュリティ・コントロールを通じて、ユーザー組織による保護対策の実施が可能だ。
推奨される保護対策に含まれるのは、エンタープライズ環境全体での AI ツールの使用状況を検査し制御する、セキュリティ・ルールの定義/作成/追加/編集など操作を含む、リモート MCP ツールの呼び出しを阻止/警告するためのポリシーの作成がある。さらに、AI 駆動型アクションに対する、最小権限原則の適用などもある。
追加の安全対策として挙げられるのは、疑わしいプロンプト使用をリアルタイムで検出するための実装および、ネットワーク全体の MCP アクティビティに関する包括的な監査ログの維持に加えて、昇格された権限での信頼できない入力の実行を阻止する、適切なプロンプト分離およびコンテキスト制御メカニズムの確立などである。
この “AI 依存型” の攻撃パターンが示すのは、企業のワークフロー全体で AI 統合が拡大する状況における、根本的なセキュリティ課題である。つまり、AI と人間の相互作用境界での、設計上の欠陥への早急な対処が必要とされている。
この “Living off AI” 攻撃手法は、生成 AI が日常業務に溶け込み始めた現場にとって、きわめてリアルな脅威になるという感じがします。MCP のような AI インターフェイスを介することで、信頼境界が曖昧になる設計上の問題は、従来の脆弱性よりも見落とされやすいはずです。なお、この記事の参照元である Cato サイトの PoC ですが、一連の操作の流れを動画で示すものとなっています。なんというか、PoC の表現方式も、テクノロジーに合わせて変化していくような感じがします。よろしければ、カテゴリ AI/ML も、ご参照ください。

You must be logged in to post a comment.