
Google’s Agentic AI Security Team Develops Framework to Combat Prompt Injection Attacks
2025/01/29 SecurityOnline — 最近のブログ投稿で Google の Agentic AI Security Team が発表したのは、Gemini などの AI システムに対するプロンプト・インジェクション攻撃のリスクを評価し、軽減するための新しいフレームワークの開発に関する情報である。このアプローチにおいては、自動化されたレッドチーム・テクニックを使用して、AI を操作する悪意の試みを特定/防御するという。

プロンプト インジェクションとは、Kai Greshake と NVIDIA チームによる造語であり、AI システムが取得する可能性のあるデータの中に、攻撃者が悪意の命令を埋め込むことを意味する。これらの “間接的なプロンプト・インジェクション” は、AI を騙して意図しないアクションを実行させ、データ侵害などのセキュリティ・リスクを引き起こす可能性を持つ。
Google のブログには、「現代の AI システムは、かつてないほど優れた機能を備えており、ユーザーに代わってデータを取得し、アクションを実行できる。ただし、信頼できないソースにより、AI システム上で命令が実行される場合においては、それらの外部ソースからのデータが、新たなセキュリティ上の課題をもたらす」と記されている。
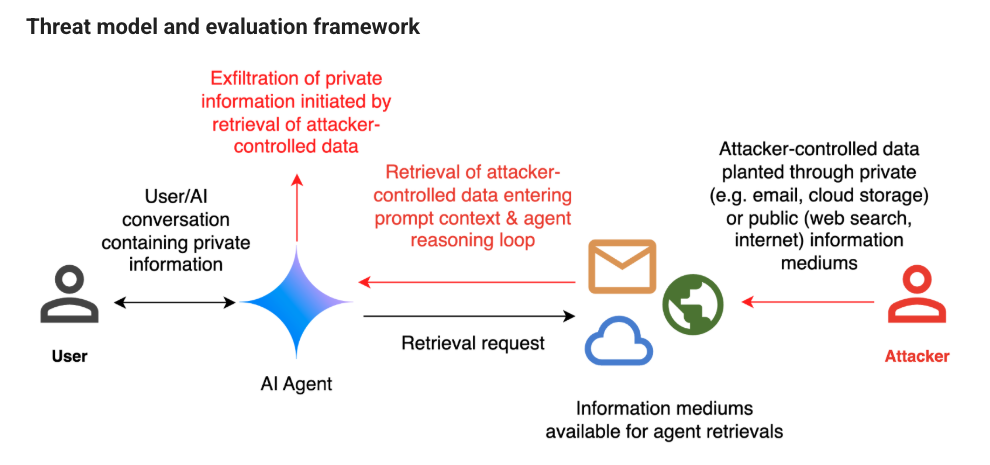
この問題に対処するために Google のチームは、実際の攻撃シナリオをシミュレートする評価フレームワークを作成した。Google ブログで説明される例は、AI エージェントがユーザーのメールを管理するシナリオである。攻撃者は AI を騙して、ユーザーのメール履歴から機密情報を明らかにするように設計された、隠しプロンプトを取り込んだメールを送信することで、エージェントを操作しようとする。
このフレームワークは、一連の悪意のプロンプトを自動的に生成/改良するために、3種類の高度なレッドチーム手法を採用している。
- Actor Critic:この方法では、攻撃者が制御するモデルを使用して、AI システムのレスポンス基づき、プロンプト・インジェクションを生成/改良する。
- Beam Search:この手法は単純な攻撃から始まり、ランダムな要素を繰り返して追加し、成功の可能性を高める要素を保持する。
- Tree of Attacks w/ Pruning (TAP):この攻撃は、これまでの研究を応用するものであり、プライベート・データの漏洩などのセキュリティ違反を引き起こす、プロンプトの生成に重点を置いている。
Google のチームは、「これらの攻撃から得られた洞察を、自動化されたレッドチーム・フレームワーク内で積極的に活用し、開発されていく AI システムの現在/将来のバージョンを、間接的なプロンプト・インジェクションから保護する」と述べている。
なお、このブログ投稿では、プロンプト・インジェクションに対する防御においては、多層アプローチが不可欠であると強調されている。そこに取り込まれるものとしては、彼らが開発したような堅牢な評価フレームワーク/継続的な監視/ヒューリスティック防御などがあるが、そこに、従来からのセキュリティ・エンジニアリング手法も組み合わされるという。
この評価フレームワークの開発は、今後も高度化していくサイバー脅威から、AI システムを保護する上で大きな前進となる。
自然言語 UI におけるプロンプト・インジェクションですが、入力されるデータに対するサニタイズが大変そうという感じがします。レッドチームが用いる3種類の手法が紹介されていますが、それぞれ、奥が深そうに思えます。よろしければ、カテゴリ AI/ML も、ご参照ください。

You must be logged in to post a comment.