
Google Chrome adds new security layer for Gemini AI agentic browsing
2025/12/09 BleepingComputer — Google が公開したのは、”User Alignment Critic” と呼ばれる新しい防御レイヤーを、Chrome ブラウザに導入する計画である。それにより、Gemini を搭載する今後のエージェント型 AI ブラウジング機能が保護されるという。エージェント型ブラウジングとは、自律的な AI エージェントがユーザーに代わって、Web 上で複数のタスクを実行する新しいモードである。具体的には、サイトのナビゲーション/コンテンツの読み取り/ボタンのクリック/フォームへの入力といった一連のアクションの実行などが自動的に実行される。

User Alignment Critic は、信頼できないコンテンツから分離/独立した LLM モデルであり、高信頼システム・コンポーネントとして機能する。
Google の AI アシスタントである Gemini は、テキスト/メディア/コードを生成できる。2025年9月から Chrome に統合され、Android や各種の Google サービスで使用されている。
その時点で Google が発表したのは、Gemini を介して Chrome にエージェント型ブラウジング機能を追加する計画であり、今回の発表は保護のための新しいセキュリティ・アーキテクチャの導入である。
Google のエンジニアである Nathan Parker が発表した新しいアーキテクチャは、間接的なプロンプト・インジェクションのリスクを軽減するものだ。間接的なプロンプト・インジェクションとは、悪意のページ・コンテンツにより AI エージェントを操作し、安全でないアクションを実行させ、ユーザー・データの公開や不正なトランザクションなどを促進するものである。
Nathan Parker によると、新しいセキュリティ・システムで採用されるのは、決定論的ルール/モデルレベルの保護/分離境界/ユーザーによる監視を組み合わせた階層型防御アプローチであるという。
この新しいアーキテクチャの主要素は以下のとおりである:
ユーザー・アライメント・クリティック:悪意のプロンプトにより汚染されない、独立した第2の Gemini モデルが、メタデータを調べて安全性を評価することで、プライマリ AI エージェントが実行しようとする全アクションを審査する。そのアクションが危険であると判断された場合や、ユーザーが設定した目標と無関係であると判断された場合には、エージェントに対する再試行の指示や、ユーザーに制御を戻すといった処理が行われる。
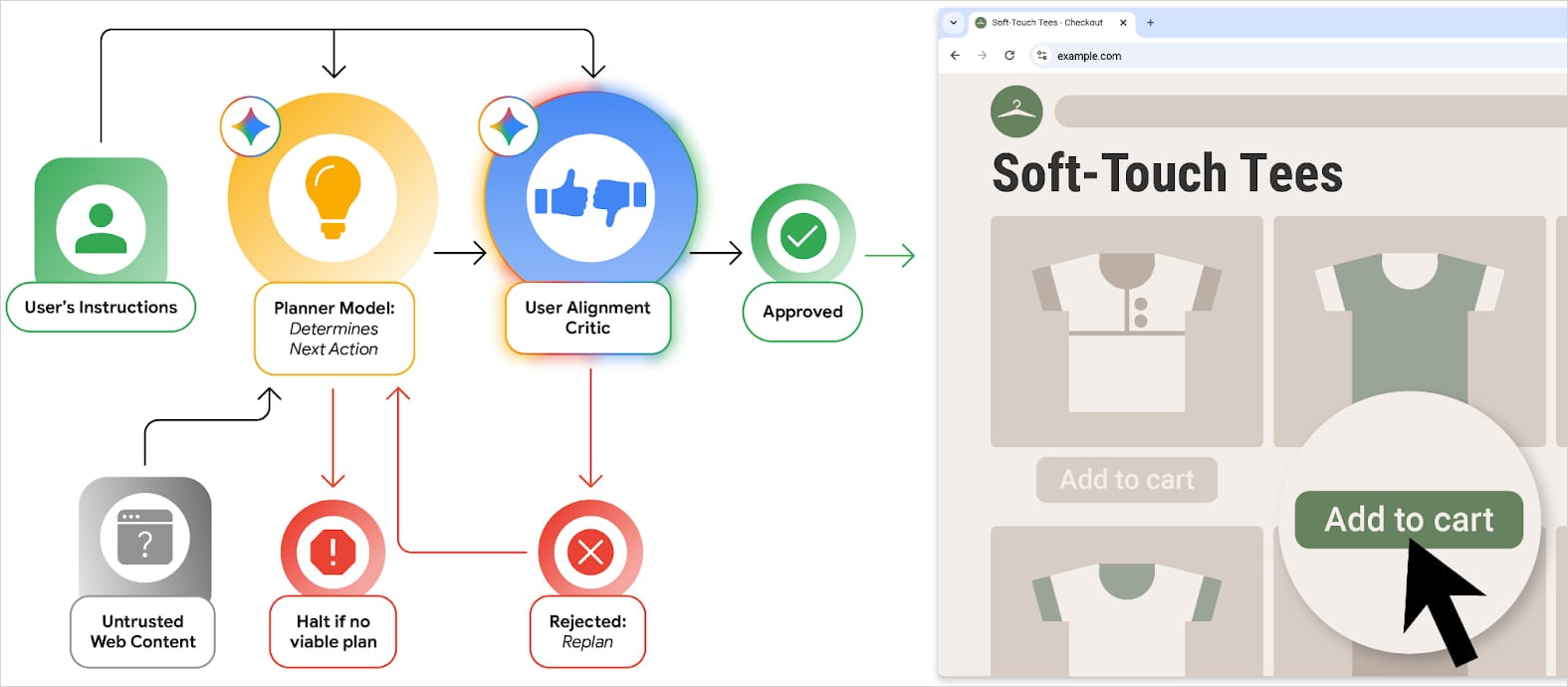
Source: Google
オリジンセット:エージェントによる Web アクセスを制限し、特定のサイトや要素とのインタラクションのみを許可する。具体的に言うと、iframe を含む無関係なオリジンが完全にブロックされ、ユーザーの意図に沿った新しいオリジンは、信頼できるゲーティング機能により承認される必要がある。それにより、サイト間のデータ漏洩が防止され、侵害されたエージェントの影響範囲が制限される。
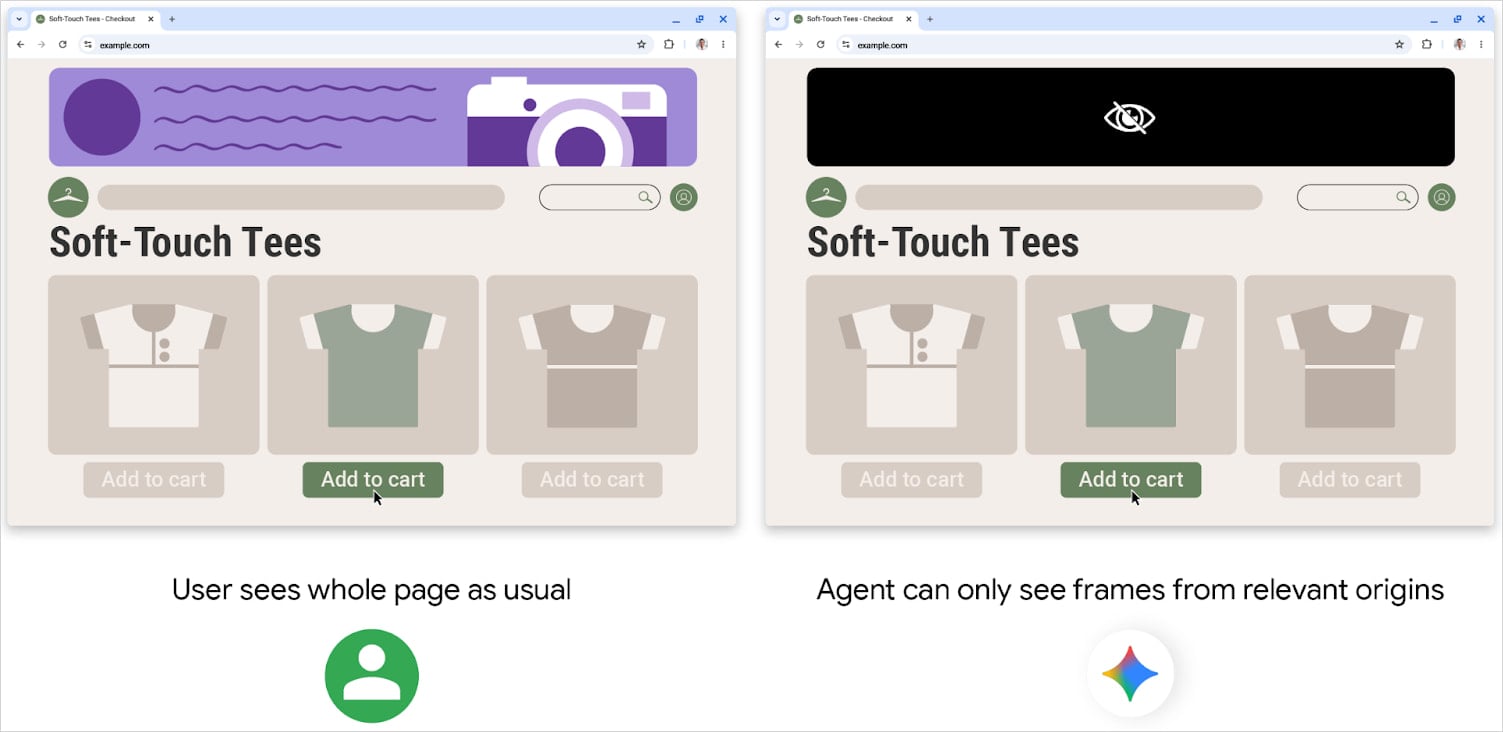
Source: Google
ユーザーによる確認:エージェントが、銀行ポータルなどの機密性の高いサイトにアクセスする場合や、保存されているパスワードなどにアクセスする場合には、Chrome によりプロセスが一時停止され、ユーザーによる手動での操作を促すようになる。
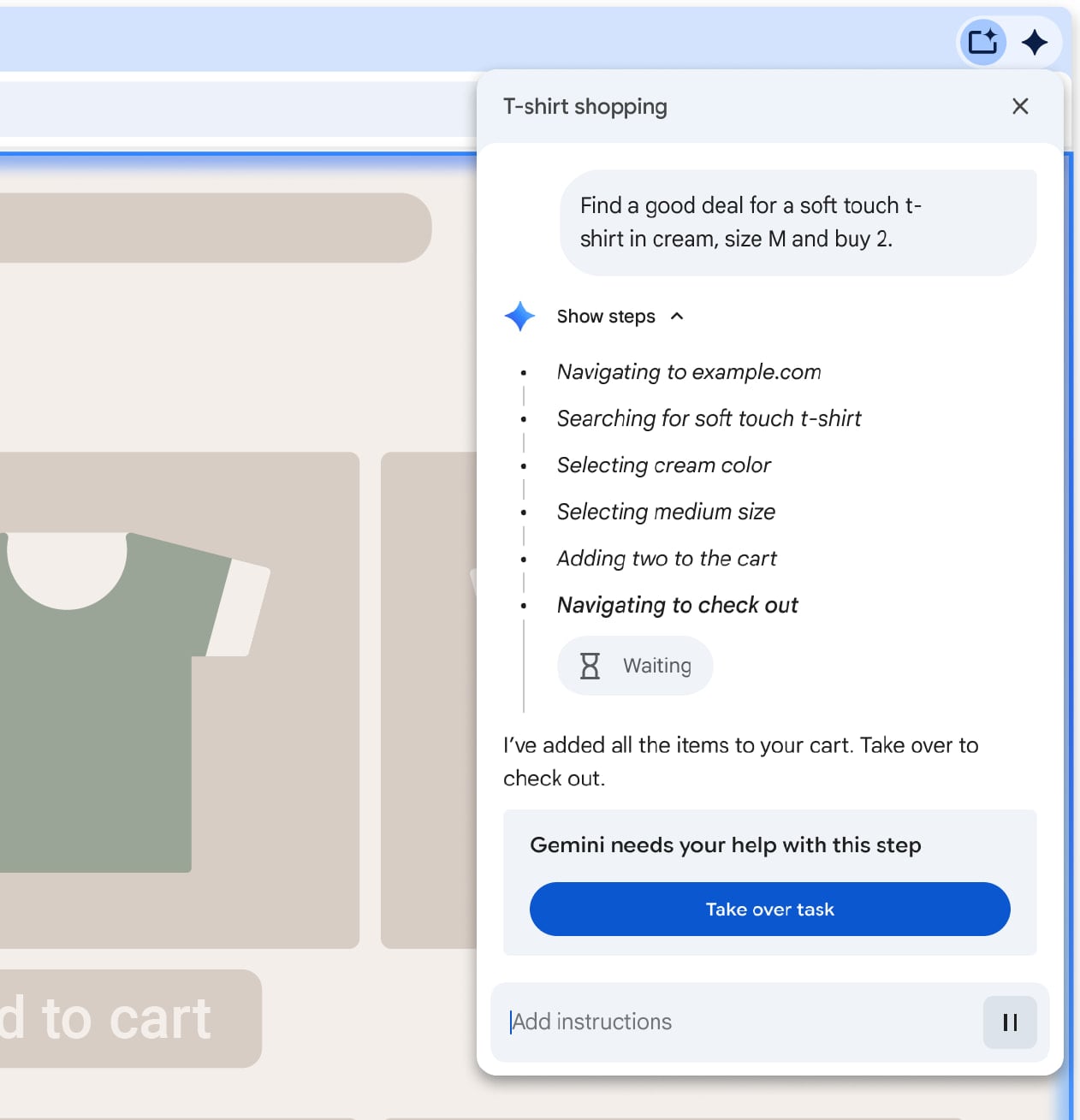
Source: Google
プロンプト・インジェクション検出:Chrome の専用分類器がページをスキャンし、間接的なプロンプト・インジェクションの試みを検出する。このシステムはセーフ・ブラウジングおよびデバイス上の詐欺検出と連携して動作し、悪意の行為や詐欺コンテンツと疑われるものをブロックする。
ーーー
エージェント・ブラウジングに対する、この階層型防御アプローチが示すのは、LLM によるブラウザへのアクセス許可に関して、類似製品のベンダーより Google が慎重であることだ。
研究者たちが主張するのは、他ベンダーの LLM が、フィッシング/プロンプト・インジェクション攻撃/偽ショップからの購入に対して脆弱であるという状況だ。
さらに Google は、テストサイトと LLM 駆動型攻撃を生成する自動レッドチーム・システムを開発し、防御の継続的テストと新しい防御策の開発を行い、Chrome の自動更新メカニズムを通じて迅速にユーザーへ提供している。
Google は、「金融取引や機密認証情報の漏洩といった、永続的な被害につながる可能性のある攻撃を優先している」と述べている。同社のエンジニアは、攻撃成功率に関するフィードバックを即座に受け取り、Chrome の自動更新により修正を迅速に提供できると付け加えている。
この分野でのセキュリティ研究を促進するために、Google は新しいシステムのハッキングに関して、最大で $20,000 の報奨金を支払うことを発表した。Chrome 上で堅牢なエージェント・ブラウジング・フレームワークを構築するための取り組みに、コミュニティの参加を呼びかけている。
AI エージェントが悪意のページに誘導され、不正な操作を実行してしまうという問題を、Google は新たな防御レイヤーを導入することで防止しようとしています。とくに、間接的なプロンプト・インジェクションが根本的なリスクとなり、意図しない行動を AI に取らせる原因を生み出しています。今回の User Alignment Critic では、独立したモデルがエージェントの行動を確認することで、安全性を担保しようとしています。AI が Web 上で自動操作を行う時代に向けて、重要な取り組みになっていくでしょう。よろしければ、Prompt Injection での検索結果を、ご参照ください。

You must be logged in to post a comment.