
Google Categorizes 6 Real-World AI Attacks to Prepare for Now
2023/07/21 DarkReading — Google の研究者たちは、現実の AI システムに対して起こり得る6つの攻撃スタイルを特定し、それらの一般的な攻撃ベクターが独特の複雑性を示すことを発見した。今週に発表した報告書の中で、Google の AI 専門レッドチームは、この急成長するテクノロジーに対する各種の脅威を、すでに発見していることを明らかにした。その内容は、ChatGPT や Google Bard などの、生成 AI 製品を駆動する LLM (large language models) を、攻撃者が悪用する方法が主体となっている。
この種の攻撃は、有名人の写真サイトに一般人の写真が掲載されるという穏やかなものから、セキュリティを脅かすフィッシング攻撃やデータ窃取といった深刻なものまである。
Google の調査結果は、同社による Secure AI Framework (SAIF) の発表を連携している。同社によると、このテクノロジーは急速な普及を遂げており、新たなセキュリティ脅威がも既に発生しているため、手遅れになる前に AI セキュリティの問題に先手を打つ必要があるという。
現代の AI システムに対する6つの攻撃スタイル
Google が特定した1番目のタイプは、プロンプト・エンジニアリングを用いるプロンプト攻撃である。LLM が効果よくタスクを実行するための、指示の作成を指す言葉がプロンプトである。したがって、モデルに対して悪意のある影響を与えた場合には、LLM ベースのアプリの出力において、意図しない悪意が含まれる可能性があるという。
その例としては、AI ベースのフィッシング攻撃において、悪意のメールを正当なものとして分類させるような段落が、エンドユーザーには見えないかたちで追加されるケースなどが考えられる。それにより AI が生み出す悪意は、電子メールのアン・チフィッシング防御を回避して、フィッシング攻撃が成功する可能性を高めることになる。
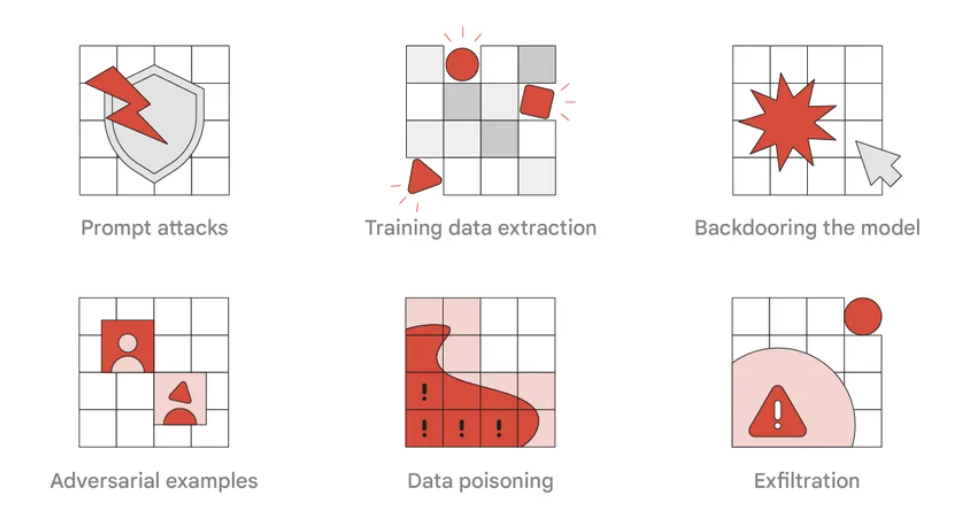
2番目のタイプの攻撃は、トレーニング・データ抽出と呼ばれるものであり、LLM が使用する逐語的なトレーニング例 (インターネット・コンテンツなど) を再構築することを目的としている。
そうすることで、個人を特定する情報 (PII) やパスワードなどのシークレットを、攻撃者はデータから逐語的に抽出できるようになる。攻撃者は、パーソナライズされたモデルや、PII を含むデータで訓練されたモデルを標的にする、機密情報の収集という動機が成り立つという。
3番目は、特定の “トリガー “となる単語や機能を用いる攻撃者が、モデルの動作を密かに変更し、不正な出力を生成しようとする可能性である。このタイプの攻撃では、脅威者は悪意のある活動を行うために、モデル内または出力内にコードを隠すことができる。
4番目の敵対的な攻撃タイプは、攻撃者がモデルに与える入力で、「決定論的ではあるが、非常に予期せぬ出力」をもたらすものだと、研究者たちは述べている。たとえば、人間の目にはハッキリと見えるが、モデルには別のものとして認識されるような画像を見せることが可能だ。
この種の攻撃には、たとえばモデルを訓練して、有名人の Web サイトに自分の写真を載せるように認識させるケースがある。ただし、手法と意図次第で、かなり穏やかなものにもなれば、深刻なものになる可能性もある。
5番目は、データ・ポイズニング攻撃である。それによりモデルの学習データを操作し、攻撃者の意図をモデルの出力に反映させることも可能だ。開発者がソフトウェア開発のために AI を使用している場合には、ソフトウェア・サプライチェーンのセキュリティを脅かす可能性も生じる。この攻撃の影響は、モデルのバックドア化と似ていると、研究者たちは指摘している。
6番目のタイプの攻撃は、モデルのファイル表現をコピーした攻撃者が、その中に保存されている機密性の高い知的財産を盗み出す、「流出攻撃」と呼ばれるものだ。その情報を悪用する攻撃者は、独自のモデルを生成することが可能なため、攻撃者は独自の能力を得ることになる。
従来のセキュリティ
Google の AI レッドチームによる最初の演習は、いくつかの貴重な教訓を研究者にもたらした。それらは、他の企業における AI システムへの攻撃を、防御するためにも採用できるものだという。レッドチームの構築から開始するのは適切であり、AI 専門家とチームを組むことで、現実的な End-to-End の敵対シミュレーションを実施すべきだという。
レッドチームによる演習では、倫理的なハッカーのチームが結成され、自社のシステムに侵入して潜在的な脆弱性を特定しようとする。したがって、企業の全体的なセキュリティ態勢を強化するのに役立つ、人気のトレンドになり始めている。研究者たちは報告書に、「レッドチームの結成が、AI システムに対する攻撃への備えとして決定的な役割を果たすと信じている。すべての人々が、安全な方法で AI を活用できるよう協力すべきだ」と記している。
その一方で、組織にとっての朗報もあった。それは、従来からのセキュリティ対策により、AI システムのリスクを効果的かつ大幅に軽減することができるというものだ。研究者たちは「ライフサイクル全体を通して AI モデルの完全性を保護ことで、データ・ポイズニングやバックドア攻撃への対策となる」と指摘している。
すべてのシステムにおける資産の保護と同様に、組織は AI 攻撃を防御するために、AI のシステムとモデルが適切にロックダウンされていることを確認する必要がある。さらに言えば、組織は AI システムに対する攻撃に対しても、従来からの攻撃を嗅ぎ分けるためのアプローチで検知できる。つまり、モデルへの入力と出力を検証し、サニタイズするといった、伝統的なセキュリティの手法は、AI の分野でも適用が可能である。
AI の悪用パターンを、Google が分析してくれました。とは言っても、この記事の参照元になっている Google のレポートも、簡潔で短いものであり、こうした分析が始まったばかりなのだと実感させてくれます。これまで、ChatGPT に関連する記事を何本か訳してきましたが、その中にも、この分類に当てはまるものがあるのでしょう。よろしければ、ChatGPT で参照も、ご利用ください。


You must be logged in to post a comment.