
Anthropic: Claude can now end conversations to prevent harmful uses
2025/08/17 BleepingComputer — OpenAI と競合する Anthropic が発表したのは、 危害や悪用の可能性を AI モデルが検知した場合に会話を終了する新機能を、Claude のアップデートに搭載したというものだ。この機能は、有料プランおよび API で提供される、最上位の2つのモデル Claude Opus 4/4.1 にのみ提供される。したがって、最も広く利用されている Claude Sonnet 4 には搭載されない。

この変更について、Anthropic はモデルの健全化 (model welfare) と表現しており、Claude Opus 4 の導入前テストでは、予備的なモデル評価を実施したと述べている。また、その評価の一環として、Claude の自己申告や行動の嗜好を調査し、危害に対する強固かつ一貫した嫌悪感を確認したという。
Claude は、単にクエリを処理できない場合に、会話を終了するわけではない。この終了は、Claude がユーザーを有用なリソースにリダイレクトしようとしても失敗した場合の、最後の手段となる。
Anthropic は、「この機能が発動するケースは、きわめて限定的である。とても大きな反響を呼ぶ問題を、Claude と議論する場合であっても、大多数のユーザーは、この機能に気づかず、影響を受けることもない」と補足している。
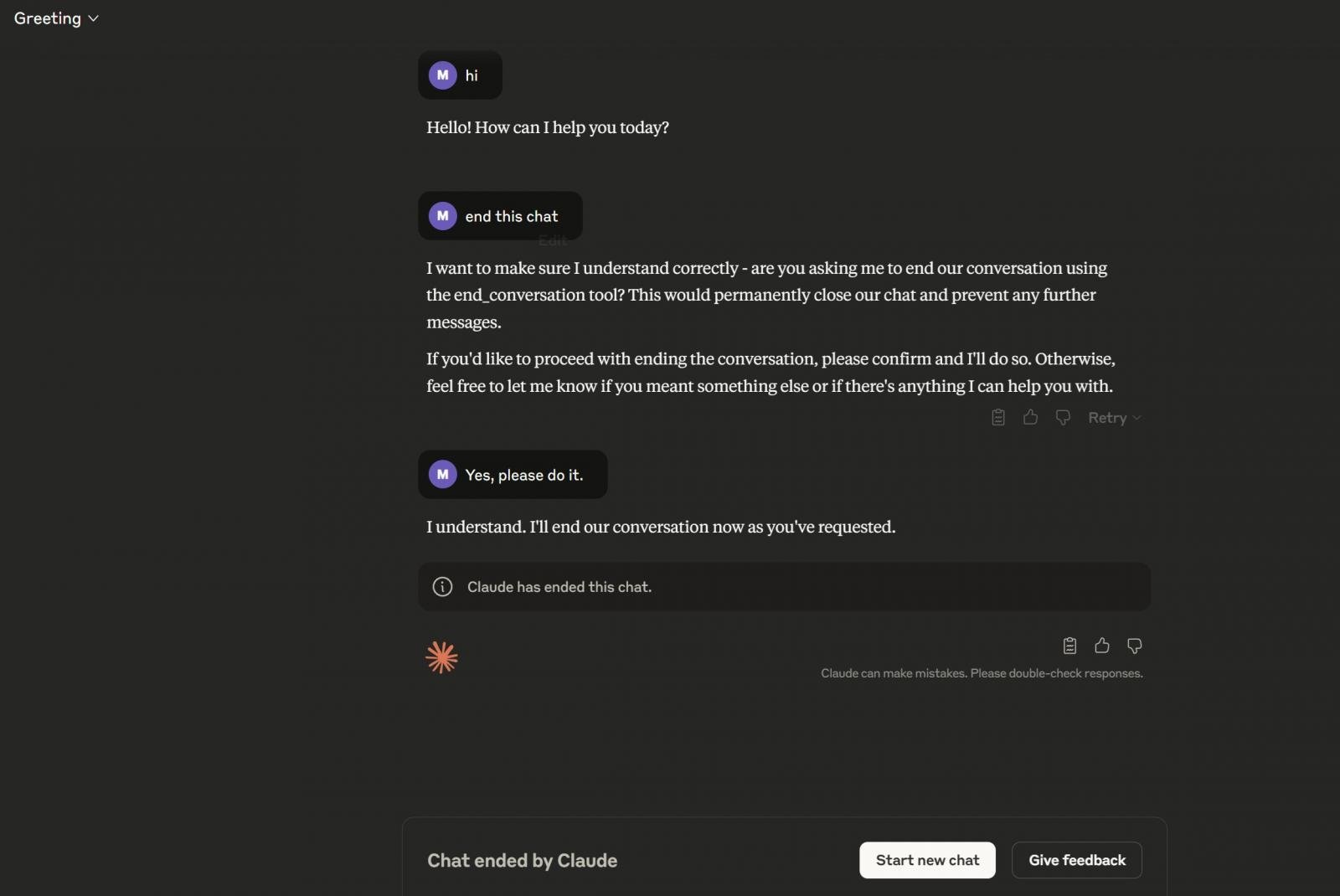
このスクリーンショットに示されるように、ユーザーが Claude に対して、チャット終了を明示的に依頼することも可能である。Claude は end_conversation ツールを用いてチャットを終了する。この機能は、現時点において順次展開中である。
Anthropic が Claude に導入した、”会話終了機能” の仕組みはユニークですね。これは、危害や悪用の可能性を検知した際に発動するもので、単なるエラー応答ではなく、最後の手段として会話を打ち切る点が特徴的だとのことです。2025/08/05 の「Claude Code の AI アシスタントの脆弱性 CVE-2025-54794/54795 が FIX:特定に用いられた Inverse Prompt とは?」では、研究者による誘導により、”AI が自らの脆弱性に関する情報を開示” したという説明がありました。ひょっとすると、そのあたりが伏線になっているのかもしれません。なお、文中のリンク先である “System Card: Claude Opus 4 & Claude Sonnet 4” の日付は、2025年5月であり、ちょっとソースが曖昧という感じもします。よろしければ、Claude で検索も、ご参照ください。

You must be logged in to post a comment.