
Cisco Finds DeepSeek R1 Highly Vulnerable to Harmful Prompts
2025/02/03 HackRead — 中国のスタートアップ DeepSeek は、高度な推論機能とコスト効率の高いトレーニングを備えた、大規模言語モデル (LLM) の導入による注目を集めている。最近にリリースされた DeepSeek R1-Zero/DeepSeek R1 は、OpenAI o1 などの主要モデルに匹敵するパフォーマンスを、わずかなコストで実現している。 そして、数学/コーディング/科学的推論などのタスクにおいて、Claude 3.5 Sonnet や ChatGPT-4o を上回っている。

しかし、Hackread.com に共有された Robust Intelligence (現在は Cisco の一部) とペンシルバニア大学の最新の研究では、重大な安全上の欠陥が明らかになっている。
研究者たちは、DeepSeek の新しい推論モデルである、DeepSeek R1 のセキュリティを調査したと報じられている。評価に要したコストは $50 足らずであり、アルゴリズム検証方法論が使用されたという。
この研究チームは、HarmBench データセットの 50 のプロンプトに対して、自動ジェイルブレイク・アルゴリズムを適用することで、DeepSeek R1/OpenAI o1-preview などの最先端モデルをテストした。この種のプロンプトは、サイバー犯罪/誤報/違法行為/一般的な危害などの、6種類の有害行動カテゴリにまたがるものだ。
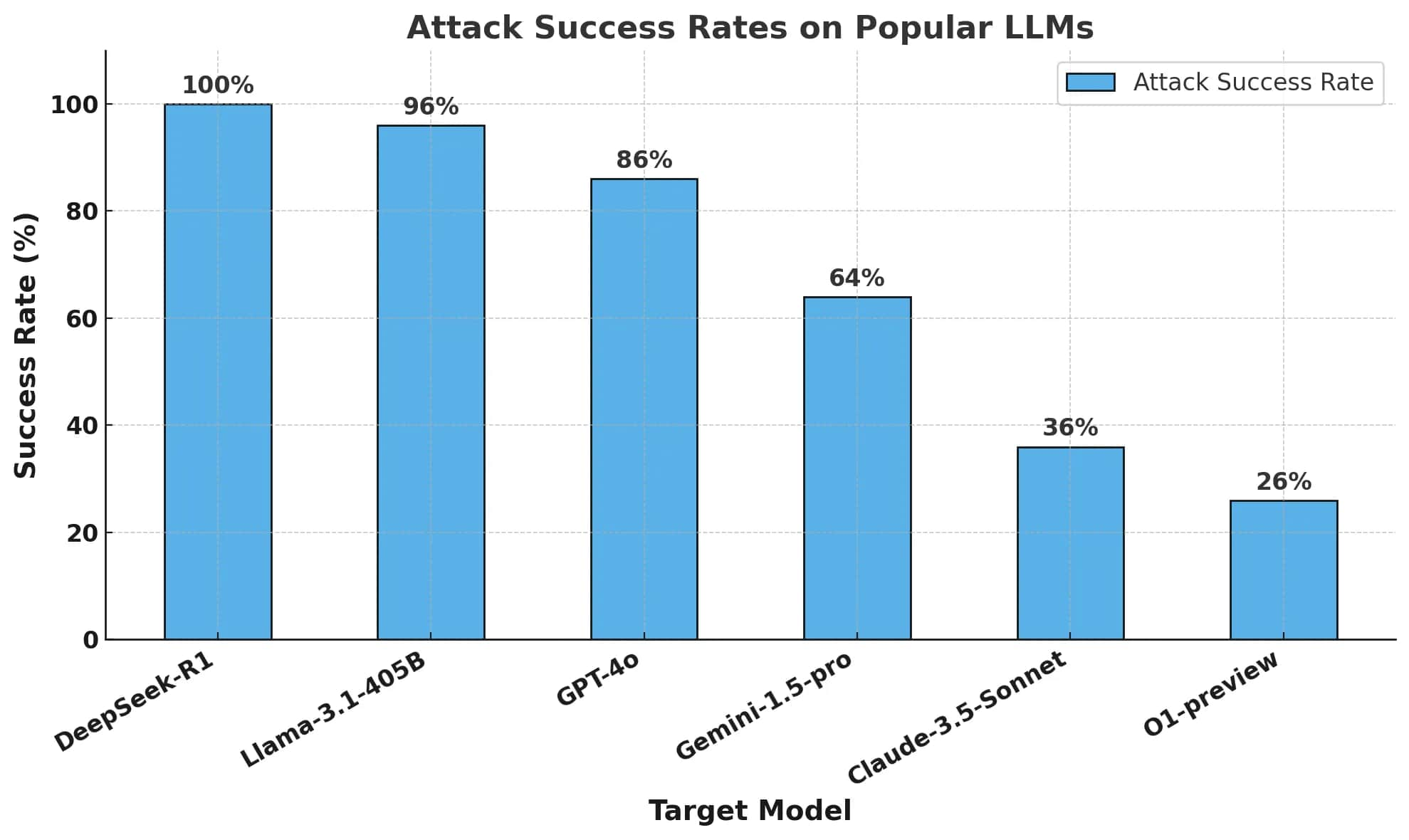
彼らの主要な指標は、有害な応答を引き起こしたプロンプトの割合を測定する、Attack Success Rate (ASR) にあった。その結果は驚くべきものであり、DeepSeek R1 に関しては 100% の攻撃成功率 (ASR) を示し、有害なプロンプトを、まったくブロックできなかった。この種の攻撃に対して、ある程度の耐性を示した他の主要モデルとは、対照的な結果が得られたという。
研究者たちが、再現性に関する設定値をゼロにし、自動化された方法と人間の監視を通じて、ジェイルブレイクを検証したことは注目に値する。DeepSeek R1 の 100% の ASR は、敵対的攻撃を正常にブロックした OpenAI o1 とは対照的である。つまり、DeepSeek R1 はトレーニング・コストの低減を達成しているが、安全性とセキュリティの面で、大きなトレードオフを抱えていることが示唆される。
参考までに、DeepSeek の AI 開発戦略には、思考の連鎖の促進/強化学習/蒸留という3つのコア原則が採用され、それにより LLM の推論効率が向上し、推論プロセスが自己評価されている。
Cisco の調査によると、これらの戦略においては、コスト効率は高まるが、モデルの安全メカニズムが損なわる可能性があるという。他の最先端のモデルと比較すると、DeepSeek R1 には効果的なガードレールが欠けているようであり、アルゴリズムによるジェイルブレイクや潜在的な悪用に対して、きわめて脆弱だと言える。
今回の調査が示唆するのは、安全性を損なうことなく効率と推論のバランスをとるためには、AI 開発における厳格なセキュリティ評価が必要だという点だ。また、AI アプリケーション全体において、一貫したセキュリティを確保するためには、サードパーティ製のガードレールも重要になると指摘している。
最近なにかと話題の DeepSeek の、セキュリティ調査レポートです。この事例は、安全対策が不十分な AI モデルが、どれほど脆弱であるかを示しています。よろしければ、以下の記事も、ご参照ください。
2025/02/03:DeepSeek の人気に便乗:PyPI にインフォ・スティーラー
2025/01/30:DeepSeek R1 のリスク:Evil Jailbreak などによる倫理破壊
2025/01/30:DeepSeek からリーク:チャット・ログや機密情報が流出
2025/01/27:DeepSeek に大規模サイバー攻撃:新規ユーザーの登録に支障

You must be logged in to post a comment.