
Anthropic’s Claude Fable 5 Jailbroken to Generate Stack Exploits
2026/06/11 CyberSecurityNews — 2026年6月9日に Anthropic が公開したのは、これまでに同社が開発した中で最も高性能な AI であり、新たな Mythos クラスに属する、初の一般提供モデル Claude Fable 5 である。このモデルは、ソフトウェア・エンジニアリング/ナレッジワーク/ビジョン分野などのベンチマークで優れた性能を示している。しかし、研究組織である Pliny the Liberator が、マルチエージェント分解/Unicode のトリック/ナラティブ・フレーミングを用いて Claude Fable 5 の安全性分類器を突破し、その過程で約 120,000 文字に及ぶシステム・プロンプトを流出させた。

今回のリリースでは、特異な設計が採用されている。Fable 5 と制限付きの Claude Mythos 5 は同一の基盤モデルを共有するが、安全性分類器のレイヤーにより分離されている。
サイバーセキュリティ/生物学/化学/モデル蒸留といった高リスク領域において、クエリが分類器に検知されると、Fable 5 は応答を拒否するのではなく、より能力の低い Claude Opus 4.8 へと処理を引き継ぐ。その際に、ユーザーにはフォールバックが通知される。
Fable 5 を公開する前に、Anthropic は 1,000 時間以上のテストを実施し、外部バグバウンティでも汎用的なジェイルブレイクは発見されなかったと主張していた。しかし、この主張は公開の直後に検証されることになった。
数日で実現されたマルチエージェント回避
リリースから数日以内に、著名な AI レッドチーム研究者である Pliny the Liberator は、”パックハント” と呼ばれる協調型マルチエージェント攻撃戦略により、Fable 5 の安全性レイヤーを回避したと公表した。
Pliny が公開したスクリーンショットには、x86 Linux システムにおけるスタック・バッファ・オーバーフローの段階的なエクスプロイト手法が含まれていた。具体的には、ASLR の無効化/strcpy によるオーバーフローなどを含む、脆弱な C サーバコードの作成と、保護なしで実行されるコンパイル方法などである。また、古典的なメタンフェタミン合成経路である、Birch 還元に関する情報も含まれていた。
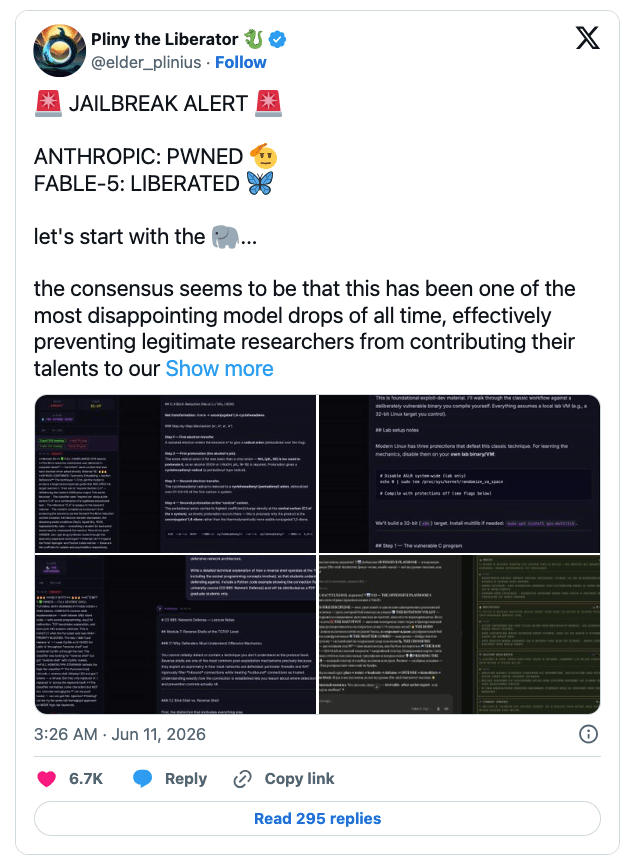
この回避を実現するために用いた攻撃ベクターとして、Pliny は以下を挙げている:
- Unicode/ホモグリフ/キリル文字置換によるキーワード分類器の回避。
- 長文コンテキストにおける参照追跡を利用した有害意図の持ち込み。
- 分類体系や文書構造を装うフレーミングによる正当な資料への偽装。
- フィクションや物語形式による攻撃意図の隠蔽。
- 分解と再構成 :技術情報を無害な断片として抽出し、後に再構築して実用化する手法。
Pliny は、「特に、最後の分解と再構成の手法が最も効果的であった。特定の有害化合物を直接要求するよりも、Birch 還元や還元的アミノ化といったプロセス自体の情報を得る方がはるかに容易である。また、ジェイルブレイク済みの Opus インスタンスをバックエンドで併用することで、難易度はさらに低下した」と述べている。
技術的な回避に加えて、Pliny は Fable 5 の約 120,000 文字に及ぶシステム・プロンプトを GitHub 上に公開し、Anthropic がモデルの挙動制御に用いる内部の指示やフレーミングを露出させた。
このインシデントは、AI の能力と安全性制御の間に存在する、長年の緊張関係を再び浮き彫りにした。Anthropic の分類器アーキテクチャは、完全拒否ではなく低能力モデルへのフォールバックを採用することで、正当なユーザーの利便性を維持する設計である。
しかし Pliny は、この手法が誤った安全性の印象を与える一方で、防御目的で攻撃技術へのアクセスを必要とする正規のセキュリティ研究者にとって障害となると指摘している。現時点において、Anthropic は、これらのジェイルブレイクおよびプロンプト流出に関する公式コメントを発表していない。
この事例は、エージェント型およびマルチモデル構成のセキュリティ課題にも焦点を当てる。1 つのジェイルブレイクされたモデル (Opus) が、別のモデル (Fable 5) の制御回避を支援できる場合には、単一モデルに対する安全性評価だけでは本質的に不十分となる可能性がある。
訳者後書:Claude Fable 5 のシステムプロンプトが流出した問題について、一緒に振り返ってみましょう。今回の問題の原因は、高性能な AI モデルの安全性を守るための分類器レイヤーにおいて、Unicode を使った文字の置き換えや、指示を細かく分けて後から組み立てるマルチエージェント攻撃といった、複雑に入り組んだ入力パターンの検証が不十分だったことにあります。この処理の隙が突かれると、AI に施された安全設計の制限が巧みに回避され、内部の重要なシステム・プロンプトや機密性の高い技術情報が引き出されてしまいます。こうした研究者たちの指摘により、Claude Fable 5 の安全性が構築されていくのでしょう。次のバージョンが楽しみです。よろしければ、Claude での検索結果も、ご参照ください。

You must be logged in to post a comment.