
Python info-stealing malware uses Unicode to evade detection
2023/03/23 BleepingComputer — PyPI 上の悪意の Python パッケージが、難読化技術として Unicode を悪用することで検出を回避し、侵害したデバイスから開発者のアカウント情報などの機密データを、盗み出して流出させている。この onyxproxy と名付けられた悪意のパッケージは、ソースコード内で複数の Unicode フォントを組み合わせて使用している。それにより、悪意の関数を特定するための、自動スキャンや文字列照合といった防御を回避していく。Phylum のサイバー・セキュリティ専門家たちが onyxproxy を発見し、その手法を説明するレポートを発表している。

このパッケージは、昨日に PyPI から削除されたことで、もはや利用できなくなったが、3月15日に同プラットフォームに公開された以降で、この悪質なパッケージは 183件のダウンロードを記録している。
Python で悪用される Unicode
Unicode は、幅広いスクリプトや言語を網羅する、包括的な文字エンコーディング規格であり、10万以上の文字をカバーする共通の規格のもとに、さまざまなセットやスキームを統一している。Unicode は、エンコーディング競合やデータ破損を排除するために作成されたものであり、異なる言語やプラットフォーム間での相互運用性と、一貫したテキスト表現を維持している。
この onyxproxy パッケージには、Unicode 文字を混在して使用する、数千の疑わしいコード文字列を含む “setup.py” パッケージが含まれている。
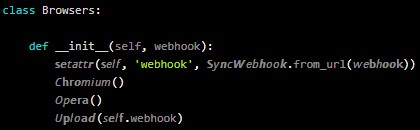
これらの文字列を構成するテキストは、フォントが違っていても、目視ではほぼ正常に見える。しかし、これらの文字を、根本的に異なるものとして解析/認識する Python インタプリタにとっては、大きな違いになる。
Phylum によると、Unicode は異なる言語や数学などに対応するために、たとえば、文字 “n” は5種類の、文字 “s” には 19種類のバリエーションがあるとのことだ。したがって、”self” という識別子を表現するだけでも、Unicode には 122,740 (19 x 19 x 20 x 17) 種類のバリエーションが存在することになる。
Python では識別子に対して、つまり、コード/変数/関数/クラス/モジュールなどのオブジェクトに対して、Unicode 文字の使用をサポートしているため、同一のように見えながら異なる機能を指す識別子を、コーダーは作成できることになる。
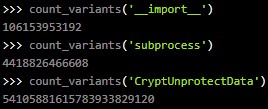
onyxproxy の場合、”import”/”subprocess”/”CryptUnprotectData” という識別子を使用しているが、それらの文字数は多く、変種が膨大にあるため、文字列照合ベースの防御を容易に破ることが可能となる。
(Phylum)
Python の Unicode サポートは、悪意の文字列の照合を回避するために簡単に悪用され、無害に見えるコードであっても、悪意の動作を実行するものが生じる。今回のケースでは、開発者から機密データや認証トークンを盗み出すという動作を実行する。
この難読化手法は、特に高度なものではないが、この手法が野放しになっているのを見ると心配になり、また、Python の難読化のために Unicode が広く悪用される兆しとも思えてくる。この難読化コードを考えた作者が誰であれ、Python インタプリタの内部を悪用することで、新種の難読化コードを生成する方法を知っているほど、賢い人物だと言えるだろう。
Python における Unicode のリスクは、過去においても Python 開発コミュニティで広く議論されてきた。以前にも、複数の研究者や開発者が、Python で Unicode がサポートされると、プログラミング言語が新しいクラスのセキュリティ・エクスプロイトに対して脆弱になり、提出されたパッチやコードの検査が難しくなると警告していた。
2021年11月には、学術研究者が Trojan Source と呼ばれる理論的な攻撃を発表し、Unicode の制御文字を悪用してソースコードに脆弱性を注入する一方で、人間のレビュアーによる悪意の注入の検出が難しくなることを証明している。
結論として、現時点において、この種の攻撃が確認されている。したがって、これらの新たな脅威に対して防御者は、より強固な検出メカニズムを実装する必要がある。
ソースコードにおける Unicode 利用が、とても解決し難い難題を突きつけています。この問題は、ほんとうに根本から解決できるのでしょうか。現状においても、悪意のパッケージに悩まされる、PyPI の運営者が可哀想になります。よろしければ、PyPI ページを、ご参照ください。


You must be logged in to post a comment.