
ChatGPT Subs In as Security Analyst, Hallucinates Only Occasionally
2023/02/16 DarkReading — 今週に発表された調査結果によると、人気の Large Language Model (LLM) である ChatGPT は、その AI モデルが特定のアクティビティのために訓練されていなくても、潜在的なセキュリティ・インシデントのトリアージや、コード内のセキュリティ脆弱性を見つける防御者にとって、有益であると示唆される。
Kaspersky の Incident Response Team Lead である Victor Sergeev は、ChatGPT のインシデント対応ツールとしての可能性を分析し、感染したシステム上で動作する悪意のあるプロセスを、ChatGPT が特定できることを 2月15日に公表した。Sergeev は、Meterpreter エージェントと PowerShell Empire エージェントをシステムに感染させ、一般的な敵対者の役割としての手順を踏んだ後に、ChatGPT を搭載したスキャナを実行した。

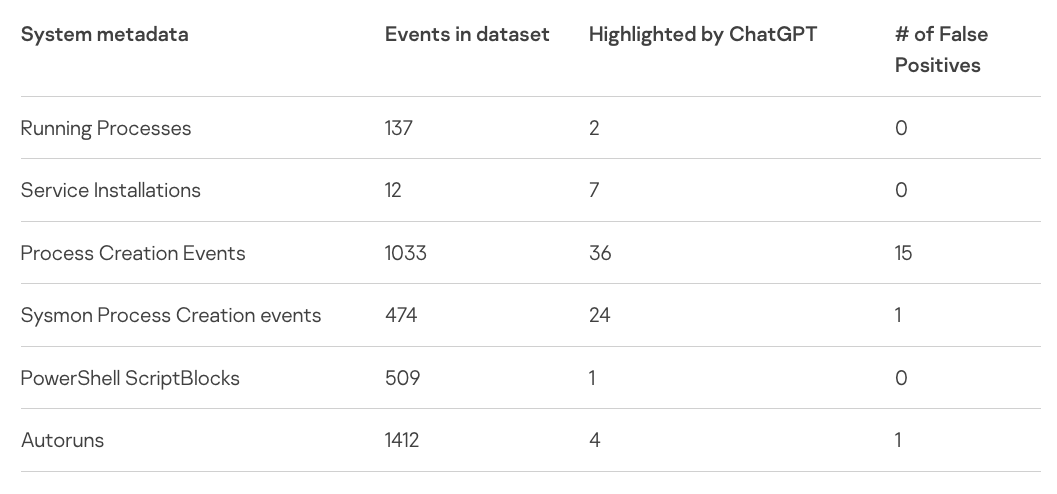
すると、この LLM は、システム上で動いている2つの悪意のプロセスを特定する一方で、137 の良性プロセスを正しく無視した。したがって、オーバーヘッドを大幅に削減できる可能性があると、この実験についてブログ記事に記している。
Sergeev は、「ChatGPT は、偽陽性を発生させることなく、疑わしいサービスを識別することに成功した。また、2つめのプロセスに関しては、そのサービスが侵害されているという指標と理由についての結論を提供した」と述べている。
羽前から、セキュリティ研究者と AI ハッカーの両者は、この ChatGPT に対して関心を持ち、LLM の弱点を探ってきた。その一方で、サイバー犯罪者たちは、LLM をダークサイドへと誘い込み、より優れたフィッシング・メールのメッセージの生成や、マルウェアの生成のために訓練しようとしている。
しかし、セキュリティ研究者たちは、この一般化した言語モデルが、特定の防衛関連タスクで機能する方法についても注目している。2022年12月には、デジタル・フォレンジック企業の Cado Security が ChatGPT を使用して、あるインシデントにおける JSON データを介して侵害のタイムラインを作成し、優れた (ただし完全に正確ではない) レポートを作成した。また、セキュリティ・コンサルタント会社の NCC Group は、コードに含まれる脆弱性を発見するために ChatGPT を実験的に使用し、それに成功したが、必ずしも正確ではなかった。
NCC Group の Chief Scientist at Security Consultancy である Chris Anley は、「セキュリティ・アナリスト/リバース・エンジニア/開発者たちが LLM を使う際には、自分の能力の範囲外のタスクについて注意が必要という結論になる。また、セキュリティ・コード・レビューについては、ChatGPT を使うべきではない。最初から完璧であることを期待するのは、ちょっと不公平だ」とも述べている。
AI で IoC を分析する
Kaspersky の実験は、Mimikatz や Fast Reverse Proxy といったハッキング・ツールについて、ChatGPT に質問することから始まったという。この AI モデルは、それらのツールの説明に成功したが、既知のハッシュやドメインを特定するよう要求されると、失敗した。たとえば、この LLM は、WannaCry マルウェアの著名なハッシュを識別できなかった。
その一方で Kasperky の Sergeev は、ホスト上の悪意のコードの特定には成功したとしている。彼は、システムからメタデータと侵害の指標を収集し、LLM に提供する PowerShell スクリプトを作成するよう ChatGPT に依頼した。Sergeev は、手動でコードを改良した後に、このスクリプトを感染させたテスト・システム上で使用した。
Sergeev は、テスト・システムの 3,500以上のイベントのメタデータを ChatGPT で分析し、74 の潜在的な侵害の指標を見つけたが、そのうちの 17 は誤検出だった。この実験から、Endpoint Detection and Response (EDR) システムを実行していない企業における、フォレンジック情報の収集/難読化されたコードの検出/バイナリコードのリバースエンジニアリングなどで、ChatGPT が有効であることが示唆された。
彼は、「この不正確な情報が、きわめて現実的な問題になることを警告している。結局のところ、予想外の結果を生み出しやすい、統計的ニューラル・ネットワークに過ぎない」と述べている。
Cado Security の分析は、「ChatGPT は通常、その結果の信頼性を限定しないと警告している。それは、OpenAI 自身が提起した、ChatGPT に関する共通の懸念である。つまり、幻覚を引き起こす可能性があり、その場合には、自信を持ってそうする」というものだ。
フェアユースとプライバシー・ルールの明確化が必要
今回の実験では、OpenAI の ChatGPT システムに提供されるデータに関しても、いくつかの重大な問題が提起されている。すでに、インターネット上の情報を利用したデータセットの作成に異を唱える企業が出始めており、Clearview AI や Stability AI といった企業は、機械学習モデルの利用抑制を求める訴訟に直面している。
プライバシーにも問題がある。セキュリティ専門家たちは、提供された侵害の指標が機密データを暴露していないか、そして、解析のためにソフトウェア・コードを提出することが、企業の知的財産を侵害していないかを判断する必要があると、NCC Group のAnley は述べている。
彼は、「ChatGPT にコードを提供することが、良いアイデアであるかどうかは、状況により大きく異なる。多くのコードはプロプライエタリあり、さまざまな法的保護の下にある。したがって、許可を得ていない限り、第三者にコードを提供することは勧めない」と述べている。
Sergeev も同様の警告を発している。彼は、「ChatGPT を使用して侵害を検出すると、必然的に機密データがシステムに送信されるため、企業ポリシーに違反する可能性が生じる。したがって、ビジネス・リスクがもたらされる可能性がある。つまり、スクリプトなどを使用することで、機密データを含むデータを、OpenAI に送信することになる。事前に、システムの所有者に相談するなどの注意が必要だ」と述べている。
ChatGPT をめぐる喧々諤々の議論が展開されていますが、結論を出すには、まだまだ、早すぎるのだと思います。学習/調整用のデータとして、使って良いもの悪いものを、見極める必要があるでしょう。同じ OpenAI のテクノロジーを使っているはずですが、2023/02/15 の「GitHub CoPilot への評価:AI モデルのトレーニングに開発者を利用して良いのか?」で説明されているような問題が残ります。しかし、攻撃側での ChatGPT 悪用は、すでに佳境に入りつつあるのかもしれません。少なくとも、彼らは、ChatGPT から成果をもたらすでしょう。
2023/02/10:ChatGPT がフィッシングをプッシュ
2023/02/03:ChatGPT はサイバー攻撃の中核になる?
2023/01/31:書いたのは ChatGPT なのか? 人間なのか?
2023/01/28:ChatGPT でセキュリティを強化
2023/01/25:ChatGPT:Prompt エンジニアリングへ
2023/01/24:ChatGPT 問題: AI を騙して悪用するのは簡単だ
2023/01/18:マルウェア開発:継続的な変異により検出が困難になる
2023/01/13:人工知能の倫理をバイパスするロシアのハッカーたち
2023/01/06:フィッシング/BEC/マルウェア開発に利用できる?


You must be logged in to post a comment.